一、设计背景
随着企业业务规模的扩大,数据量激增,对数据可用性、容灾能力及实时性提出了更高要求。MySQL多活架构通过跨地域部署数据库实例,实现数据同步与负载均衡,有效提升系统稳定性。数据消费服务作为多活架构的关键组件,负责从多个MySQL实例中高效、可靠地消费数据,供下游系统使用。
二、设计目标
- 高可用性:确保服务在单点故障或地域故障时仍能正常运行。
- 数据一致性:在多活环境下保证数据消费的最终一致性,避免数据丢失或重复。
- 低延迟:优化数据消费流程,确保数据实时或近实时传输。
- 可扩展性:支持水平扩展,适应业务数据量的增长。
- 容错性:具备自动故障检测与恢复机制,减少人工干预。
三、系统架构
MySQL多活数据消费服务采用分布式架构,主要包括以下组件:
1. 数据采集层
- MySQL Binlog监听器:基于Canal或Debezium等工具,实时捕获各MySQL实例的Binlog变更事件。
- 数据解析器:解析Binlog事件,转换为统一格式(如JSON或Avro),便于下游处理。
2. 消息队列层
- 消息中间件:选用Kafka或RocketMQ,作为数据缓冲与分发中心。每个MySQL实例对应一个Topic,确保数据有序性。
- 分区策略:根据业务主键分区,保证同一业务数据按顺序消费。
3. 数据消费层
- 消费者组:部署多个消费者实例,以消费者组形式订阅消息队列,实现负载均衡与故障转移。
- 数据处理器:对接收的数据进行过滤、转换、聚合等操作,并写入目标系统(如数据仓库、缓存或第三方服务)。
4. 控制与协调层
- 配置中心:使用ZooKeeper或Etcd管理消费者配置、偏移量及故障节点信息。
- 监控告警模块:集成Prometheus与Grafana,实时监控服务状态、消费延迟等指标,并设置告警规则。
四、关键设计细节
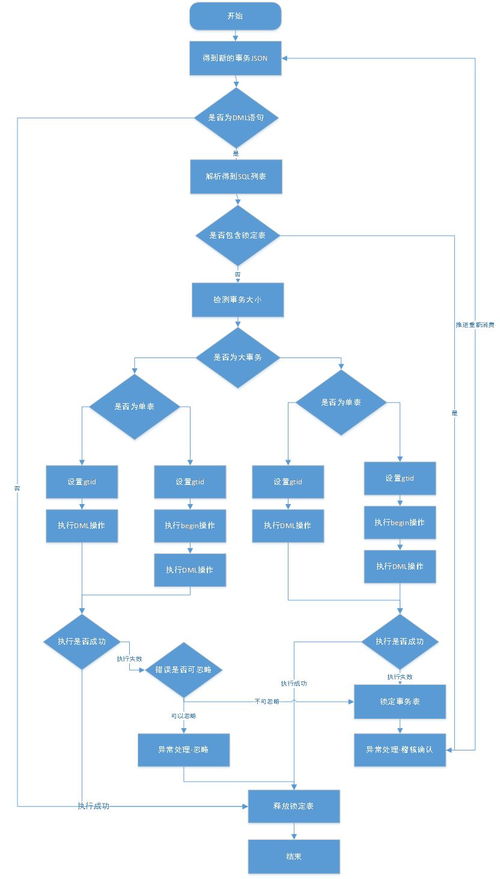
1. 数据一致性保障
- 幂等消费:消费者需实现幂等逻辑,通过业务主键或唯一标识避免重复处理。
- 事务性消息:结合本地事务表与消息队列,确保数据消费与业务处理的一致性。
- 多活冲突处理:采用“最后写入获胜”或基于时间戳的冲突解决策略,确保数据最终一致。
2. 容错与恢复机制
- 消费者偏移量管理:定期提交消费偏移量至持久化存储,故障恢复时从断点继续消费。
- 自动重试机制:对消费失败的消息进行指数退避重试,超过阈值后转入死信队列人工处理。
- 健康检查与自愈:通过心跳检测消费者实例健康状态,异常时自动重启或转移负载。
3. 性能优化
- 批量消费:消费者批量拉取消息,减少网络开销与处理延迟。
- 异步处理:采用异步非阻塞IO模型,提升并发处理能力。
- 缓存优化:对热点数据预加载至本地缓存,加速消费流程。
五、部署与运维
- 多地域部署:在各数据中心独立部署消费服务,通过全局负载均衡引流。
- 灰度发布:新版本通过金丝雀发布策略逐步上线,降低风险。
- 日志与追踪:集成ELK栈收集日志,并结合分布式追踪系统(如SkyWalking)分析链路性能。
六、总结
MySQL多活数据消费服务通过分层架构与关键设计,实现了高可用、一致且高效的数据消费能力。未来可结合流处理框架(如Flink)进一步优化实时分析场景,并探索AIops智能运维,提升系统自治能力。